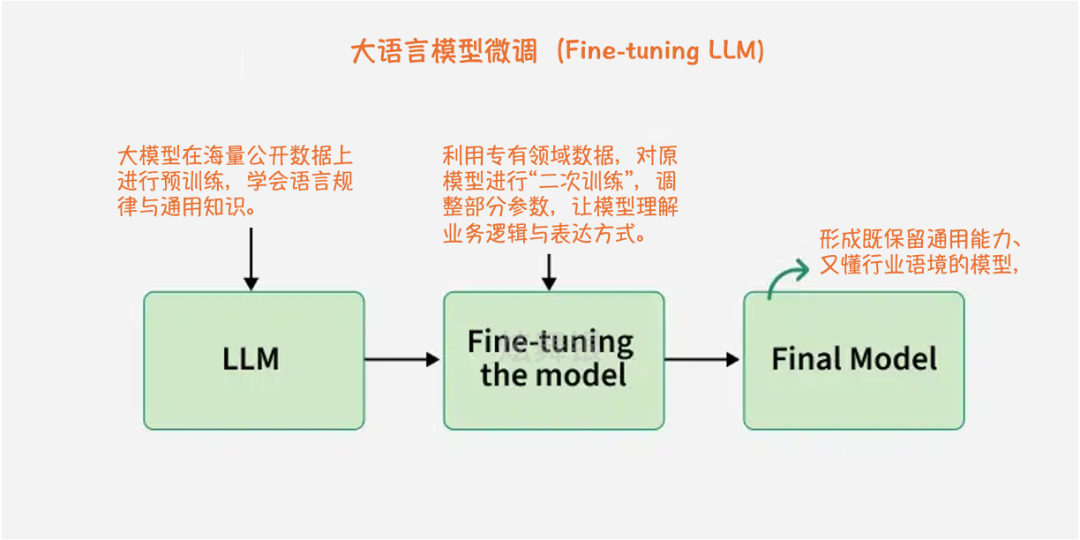
如何从视频提取提示词
如果你想稳定地 get prompt from video,不要从零空想提示词。更高效的方法是先选一段参考视频,拆解场景逻辑,再转成结构化提示词包。这样做能保留运动、构图和节奏信息,结果可控性更高。一个合格的 video to prompt generator 通常应一次输出主提示词、短提示词、负面提示词、关键词和镜头清单。

先给结论
最快的 generate prompt from video 路径是:

- 选择 8-30 秒的参考片段。
- 按镜头切分为 3-8 个 shot。
- 逐镜头描述主体、机位和光线。
- 合并为一段主提示词。
- 补短提示词和负面提示词。
- 保存关键词标签便于复用。
这样得到的是可执行的 video generation prompts,而不是随机结果。


什么时候该用 video prompt generator
以下场景特别适合:
- 复刻广告里已验证的视觉风格
- 批量产出 YouTube Shorts 开场镜头
- 统一创作者与后期的镜头语言
- 提升 AI 视频迭代速度
当团队经常说“按这个参考视频来”,prompt from video 工作流通常是把主观需求转成可执行指令的最好方法。

六步实操详解
第 1 步:选择意图明确的参考片段
优先选择目标单一的片段,如开场钩子、产品特写、转场段落。避免信息过杂的视频。

第 2 步:按镜头切分并做标签
每个镜头至少标注:

- 主体
- 运动
- 构图
- 光线
- 情绪
这是决定 video prompts ai 质量的关键环节。
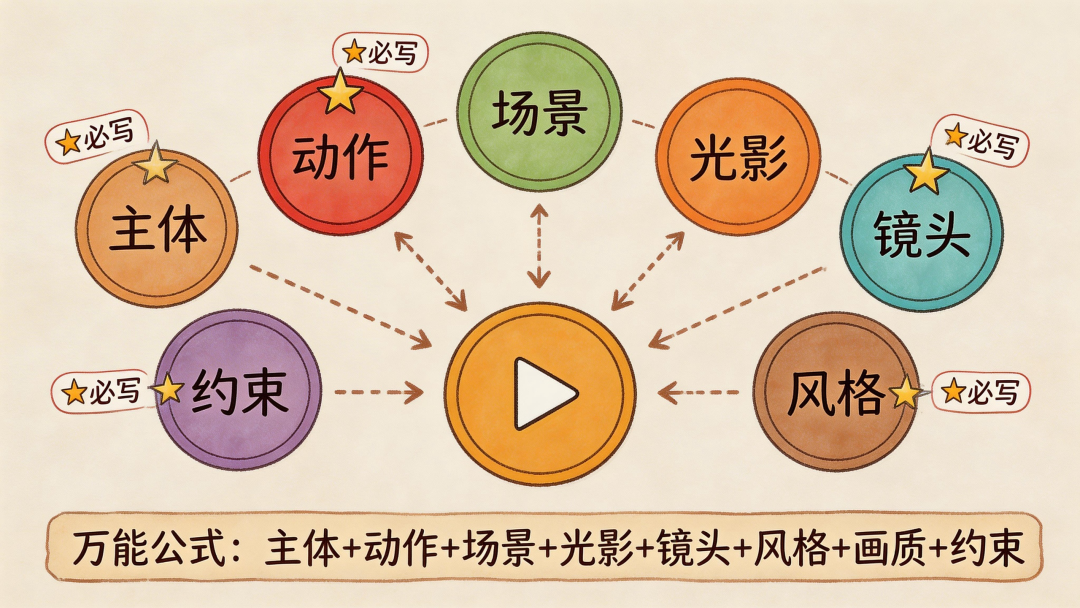
第 3 步:写镜头级提示词
推荐统一句式:
主体 + 场景 + 相机动作 + 镜头/景深 + 光线 + 情绪 + 时间推进

第 4 步:合并主提示词
把镜头句按时间顺序串成一段可执行描述,明确“先远景,再推进,最后近景”等变化。
第 5 步:补短提示词和负面提示词
- 短提示词:用于快速试错
- 负面提示词:约束常见失败(闪烁、脸部形变、手部异常、背景噪点)
第 6 步:沉淀关键词标签
每条提示词包建议保留 5-12 个标签,如 neon alley、handheld tracking、slow push-in,便于后续检索复用。
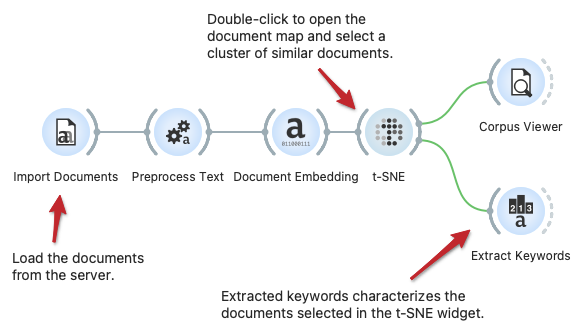
手写与结构化流程对比
| 方式 | 速度 | 一致性 | 团队复用 |
|---|---|---|---|
| 手写提示词 | 中 | 低 | 低 |
| 结构化 video-to-prompt 流程 | 高 | 高 | 高 |
重点不是把提示词写得更长,而是让结果更可预测、可复用。
常见错误
- 只写物体,不写相机运动
- 一条提示词里混入冲突风格
- 忽略负面提示词
- 关键词过于空泛(如“高级感”“电影感”)
- 团队内部没有统一命名规范
FAQ
这和 text-to-video 提示词有什么区别?
有区别。text-to-video 更偏“从想象出发”,而 get prompt from video 是“从参考素材出发”,更适合做风格复现。
一套提示词能直接用于 Runway、Kling、Sora 吗?
通常可以,但要按平台长度和语法做微调。建议保留一份统一主提示词作为基准。
提取时输入视频多长合适?
多数场景下,8-30 秒足够提取风格和镜头逻辑,同时避免噪声信息过多。

下一步
如果你要把这套流程落到团队:
- 先在 首页工具 里跑一段参考视频。
- 阅读 Video-to-Prompt 系统设计 统一输出结构。
- 配合 镜头语言框架 提升可控性。
- 发布前用 质量检查清单 做一次 QA。